一、说在前面
前段时间略读过《七周七个并发模型》这本书,收获良多,但也一直没能整理出一份学习心得。正逢新换了公司,进入互联网行业,技术氛围那是相当的浓重啊,组里这段时间流行node.js,那货处理高并发IO很牛逼,为什么呢?因为异步IO、事件驱动、Event Loop。感觉自己明白了,其实乍一想,还是不明白,想得越多,脑子里反而充斥着一堆稀里糊涂的概念:高并发,阻塞/非阻塞IO,同步/异步IO,单线程/多线程/多进程。嗯,是时候理理头绪了。因此就有了这篇文章,我试图从Kernel层的IO开始向上来解释高并发IO这件事。
Note
- IO的内核实现有比较大的平台差异,本文均以Linux为对象
- 本文主要讨论网络IO
二、Kernel-level IO
同步、异步、阻塞、非阻塞的概念是我认为最难理清的,我觉得搞清楚两点很重要:IO到底做了什么,同步异步的判断标准是什么。
同步IO vs. 异步IO
看过很多版本对于这些概念的描述,我觉得来自POSIX标准的这个判断准则最简单也最容易理解:
从发出IO操作请求开始到IO操作结束的过程中没有任何阻塞,就称为异步,否则为同步
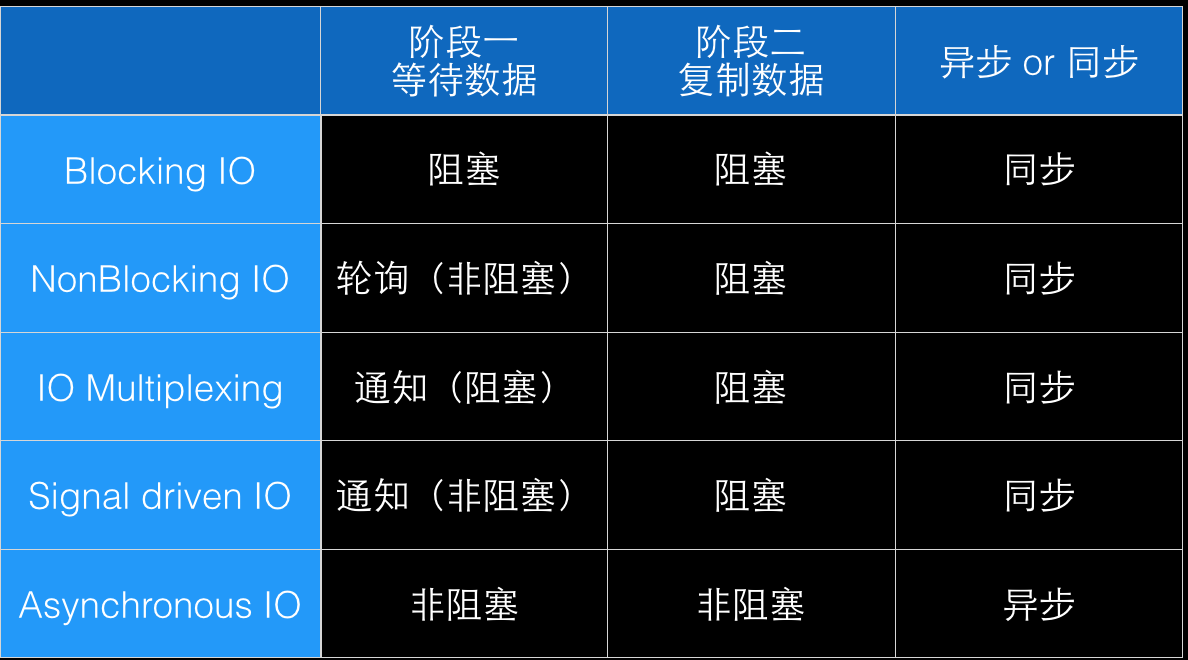
IO的两个阶段
那么,问题来了,从请求开始到操作完成,IO具体做了什么呢?其实,IO可以分为两个阶段,以socket的recv系统调用为例:
- 第一阶段、等待数据就绪
- 第二阶段、将数据从内核缓冲区复制到应用缓存区
IO模型
IO模型在不断的演化和改进中,要做一个梳理并不容易,查阅了很多资料中对于IO模型的归纳,相比觉得《UNIX网络编程 卷1:套接字联网API》这本书中所总结的五种IO模型是最为清晰和合适的。
1) 阻塞式IO
最为常用的一种IO模型,整个IO操作从发起开始一直阻塞到完成,显然,这不够高效,但模型简单容易理解。目前,Linux的系统调用默认情况下大多是阻塞式的,socket的recv系统调用也是如此。
2) 非阻塞式IO
对于网络IO来说,IO的第一阶段往往需要比第二阶段花更多的时间,所以非阻塞式IO旨在将第一阶段非阻塞化,还是以recv系统调用为例,调用非阻塞式recv时,如果数据未ready,将直接返回,反之,就阻塞式地进行第二阶段的IO。在数据未就绪的情况下通常需要结合轮询机制,保证就绪状态的IO能够被及时的处理,这对CPU的浪费也是比较大的。非阻塞式的IO可以通过设置文件描述符O_NONBLOCK标识位实现,但它仅针对网络IO有效。
3) IO Multiplexing
非阻塞式IO在遇到大量并发IO的时候(想想Web服务器的场景),CPU将忙于对所有文件描述符进行轮询检查,因为一次检查只能获知一个文件描述符的就绪状态,非常低效。随后,IO Multiplexing就实现了一次检查可以同时获取到多个文件描述符的就绪状态,通过这种方式可以大大提高就绪检查的效率。但需要指出的是,就绪检查本身是阻塞式的操作,在Linux平台,IO Multiplexing有多种实现,这里按照出现顺序来进行一一介绍。
- select:通过select系统调用,需要检查的文件描述符数据被作为参数传入,他们会在内核被修改就绪状态,返回用户态后再通过遍历找到所有就绪的文件描述符。这看起来就不是特别高效,而且它对于文件描述符数组的长度限制在1024以下。
- poll:类似于select,只是去除了文件描述符数组长度的限制。
- epoll:select和poll的主要问题是文件描述符数组需要在内核态和用户态之间进行复制,并且需要进行遍历才能获得就绪的文件描述符。epoll则利用mmap技术避免了这些复制和遍历操作。epoll在Linux2.6出现,通过epoll_ctl进行注册,然后通过epoll_wait得到就绪通知,可以做到高效地就绪状态检查,它是目前性能最好的就绪通知方案。
4) 信号驱动式IO
Linux2.4上出现了SIGIO这种就绪通知机制,它跟epoll技术有类似之处,但它是通过内核的信号机制实现非阻塞的就绪通知。乍看起来已经做到了非阻塞,但其实有不少问题,比如信号在内核的事件队列中顺序处理可能会导致延迟和丢失。
5) 异步IO
Linux2.6.16开始出现了Kernal AIO,IO操作发起时将被注册到事件队列,IO操作完成时通过信号或者轮询获取状态,但它在Linux中的实现依然是通过内核多线程来实现,但它无法利用内核缓存区,很难被用到网络IO中,总体上来说,Kernal AIO方案尚不成熟,目前也存在一些伪异步IO的方案,比如Glibc AIO、libuv和JDK7 AIO,它们都通过用户态的多线程模拟异步IO。
下面这张图整理了这五个IO模型在IO的两个阶段中是否阻塞,从而也决定了每种IO模型是同步还是异步的。
三、Network IO Concurrency Model
解释了Kernel层的IO模型,我们再自下而上来看看基于这些模型可以设计哪些网络IO并发模型,IO并发模型更多地关注在编程模型上,它们要么被程序员用以直接编写网络应用,要么被网络框架/库用来实现构建更高抽象的API。IO并发模型主要分为BIO、NIO和AIO三种。
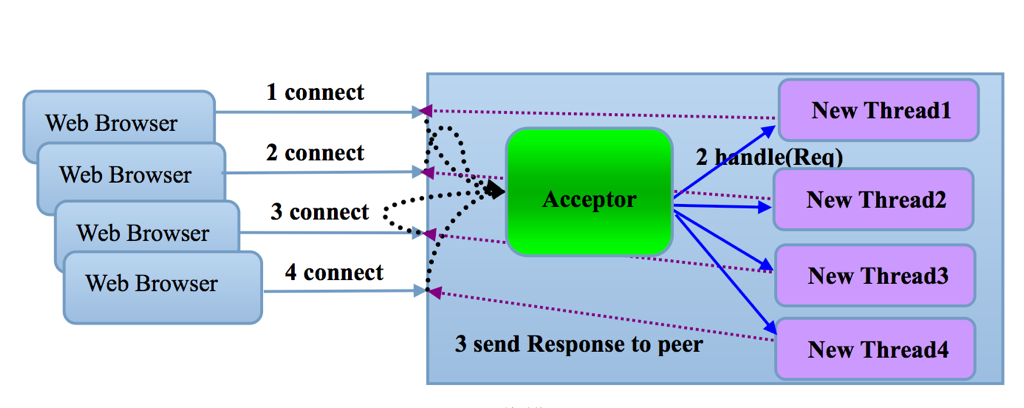
BIO
简单粗暴的”One process/thread per socket” Model,它的缺陷想必也不需要解释了,Apache和Tomcat(低于6.0.0) 是这一种并发模型的典型实现。
NIO
说到NIO,就不得不提Reactor Pattern(反应堆模式),它是一种事件驱动的设计,利用IO Multiplexing和非阻塞IO实现单线程或者少量线程对海量并发IO的处理。
它包括以下组件:
- Acceptor:也称作Selector,管理网络连接,通常基于epoll/select/poll等实现。
- Dispatcher:管理handler的注册,从Acceptor获取事件之后分发给Handler。
- Handler:请求的处理,包含读取、计算、发送等操作。
从线程模型上来看,它可以实现为单线程或者少量线程的版本:
1)单线程模型:所有操作都在一个线程中完成,当在高并发环境下,单线程负载过大,可靠性无法保证。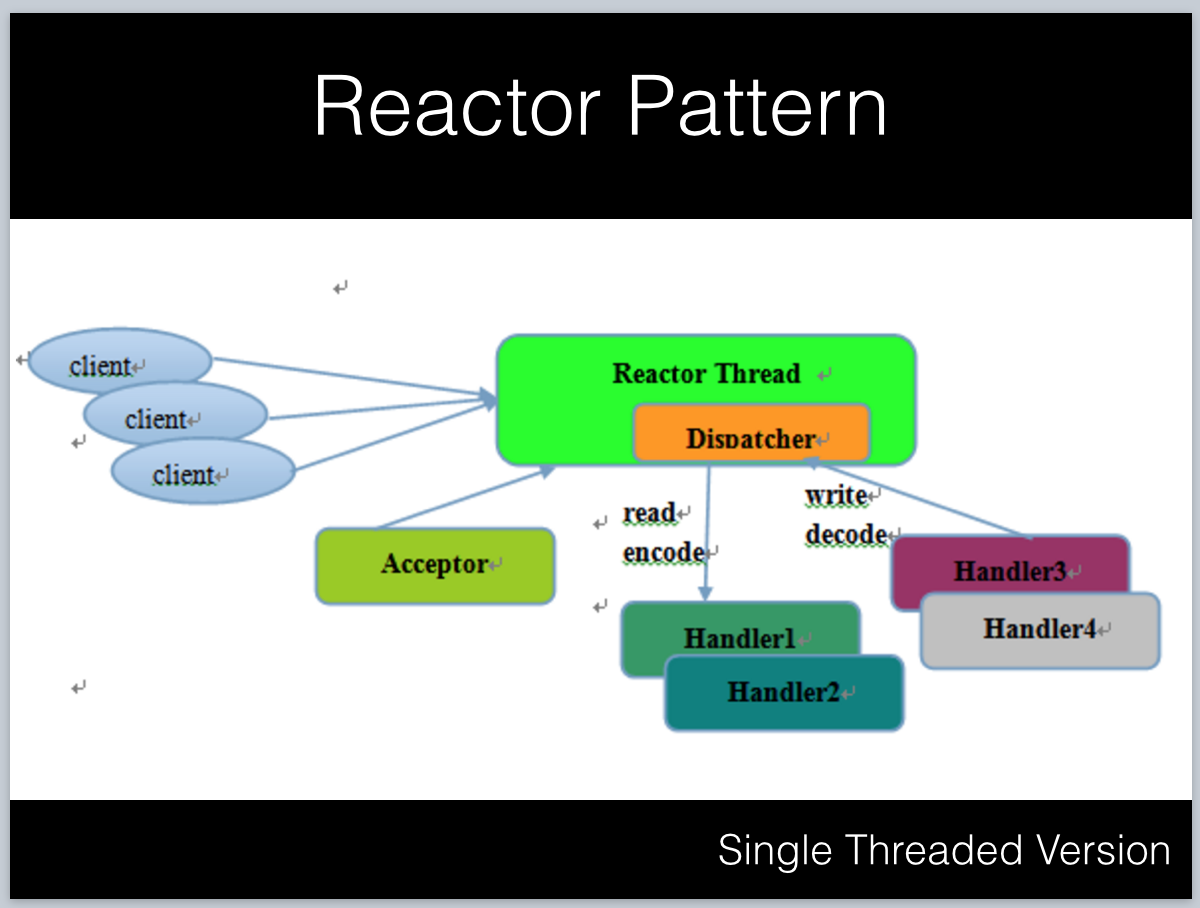
2)多线程模型:多线程模型将Acceptor运行在独立的线程,这个线程只处理IO就绪检查,网络请求的处理都在线程池中进行,当然Acceptor可以继续扩展成多个线程提高可靠性。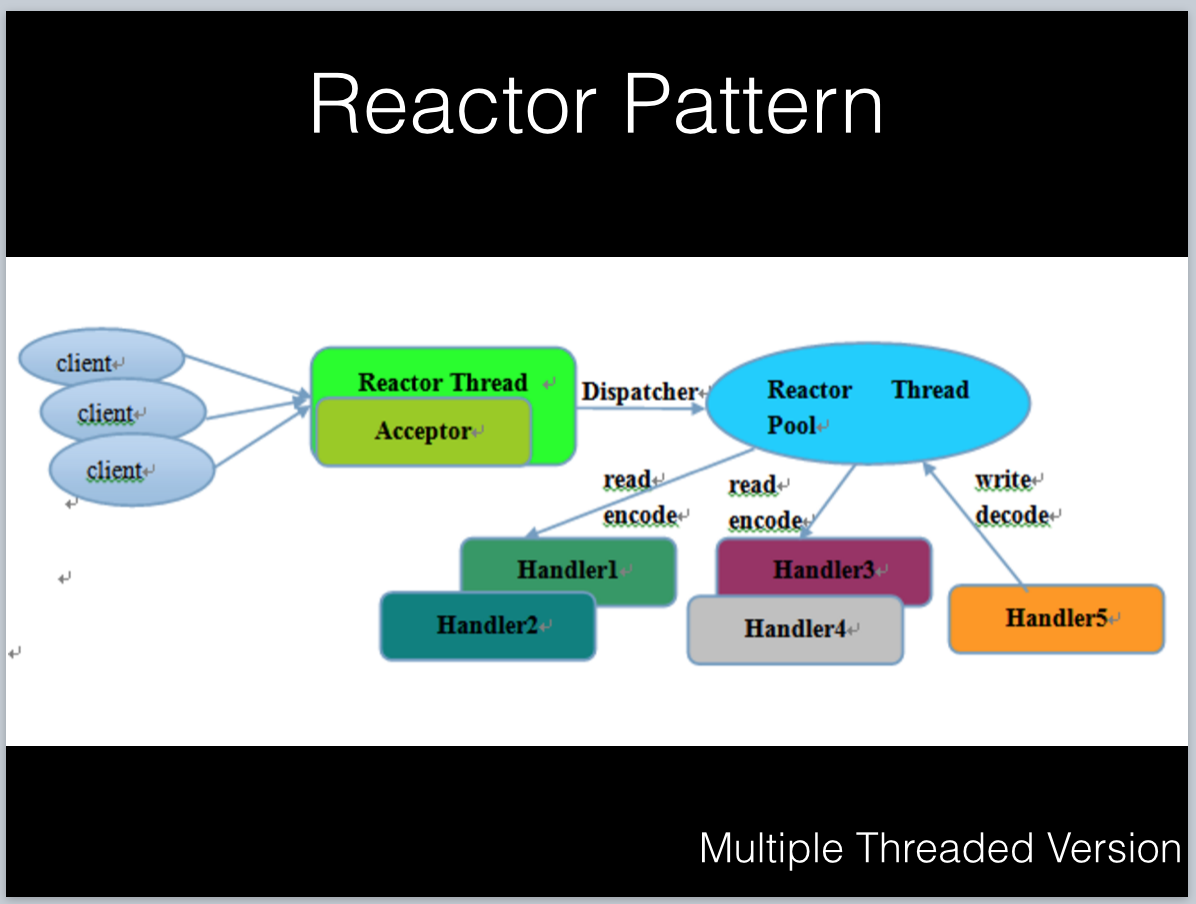
NIO的典型应用包括:Netty, libuv, EventMachine, Nginx, Tomcat6/7
AIO
AIO模型中有一个Reactor的异步版本:Proactor Pattern,它不再关注IO操作的就绪状态,而只关注IO完成的事件,由于它依赖异步IO操作,因此目前的实现大多利用线程池结合非阻塞IO实现。
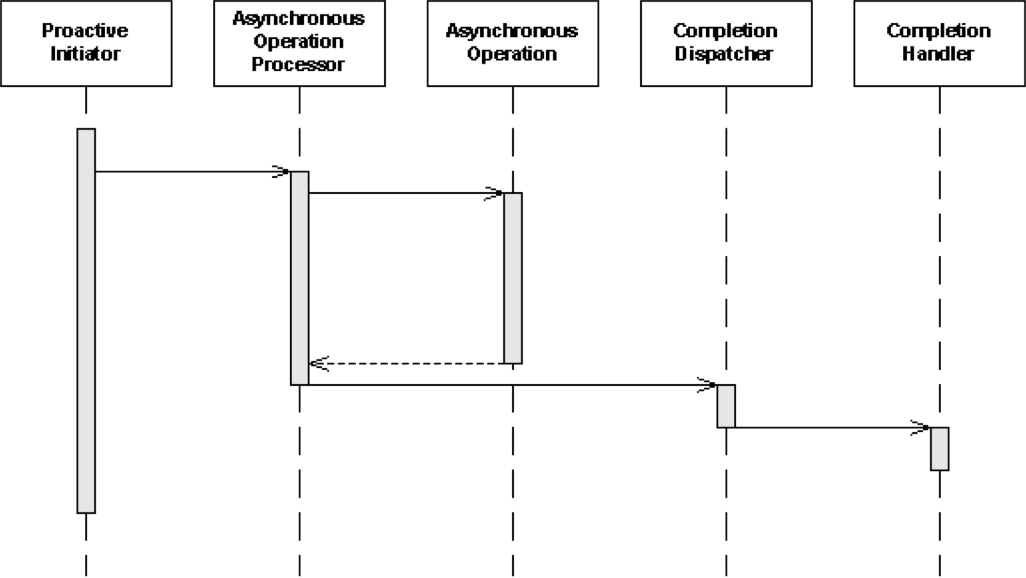
它包括以下组件:
- Proactive Initiator:定义其它组件,并发起异步操作
- Completion Handler:回调,IO完成后执行
- Asynchronous Operation Processor:负责发起异步IO,并获取IO完成通知
- Completion Dispatcher:分发IO完成通知给对应的Completion Handler
AIO模型的典型应用包括: IOCP,node.js,JDK7 AIO
四、Concurrency Model in Web/Application Server Or Network application
Apache
- fork模式:BIO, 多进程,一个进程处理一个连接,每次都fork一个新的woker进程来处理新的连接,当年的CGI就用的这种模型。
- prefork模式:BIO, 单线程+多进程,一个进程处理一个连接,利用进程池处理连接。
- work模式:BIO, 多线程+多进程,一个线程处理一个连接。
Tomcat
Tomcat可以配置不同的Connector从而采用不同的IO模型:
- Http11Protocol Connector:BIO模型
- Http11NioProtocol Connector:NIO模型,V6.0.0开始支持基于NIO模型的HTTP Connector
- Http11AprProtocol Connector: Apr即Apache Portable Runtime,从操作系统层面解决io阻塞问题。
这里引用文献11中对Tomcat8的性能测试结果1
ab -n 10000 -c 1000 localhost:8080/examples/index.jsp
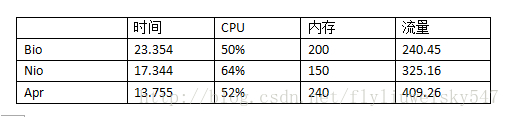
总体上来看,Apr处理请求最快,Bio最慢;Apr宽带占用最高,Bio最低;但Apr的内存占用最高,而Nio的内存占用最低
Nginx
- NIO, 一个进程(线程)处理多个连接
- 多进程(master进程+多个worker进程)+ 单线程
- 连接、接收、发送操作都在worker进程完成,master进程主要负责管理配置、升级等
- 基于epoll和非阻塞IO实现的事件驱动的IO模型
Redis
NIO,事件驱动(实现了Event Loop),单线程
Node.js
基于AIO,事件驱动,通过libuv实现(Windows平台利用了IOCP,Linux平台通过在线程池执行阻塞IO并将数据通过pipe传递给Event Loop来模拟异步IO)
Netty
一种Java NIO框架,使用NIO模型,基于典型的Reactor模式,实现了EventLoop,Selector,ChannelHandler
五、Conclusion
IO模型就先聊这些,本系列的下一篇将基于这些基础来聊聊编程语言的并发模型,尽请期待。
六、Reference

订阅我的微信公众号,您将即时收到新博客提醒!